Advanced Crawler
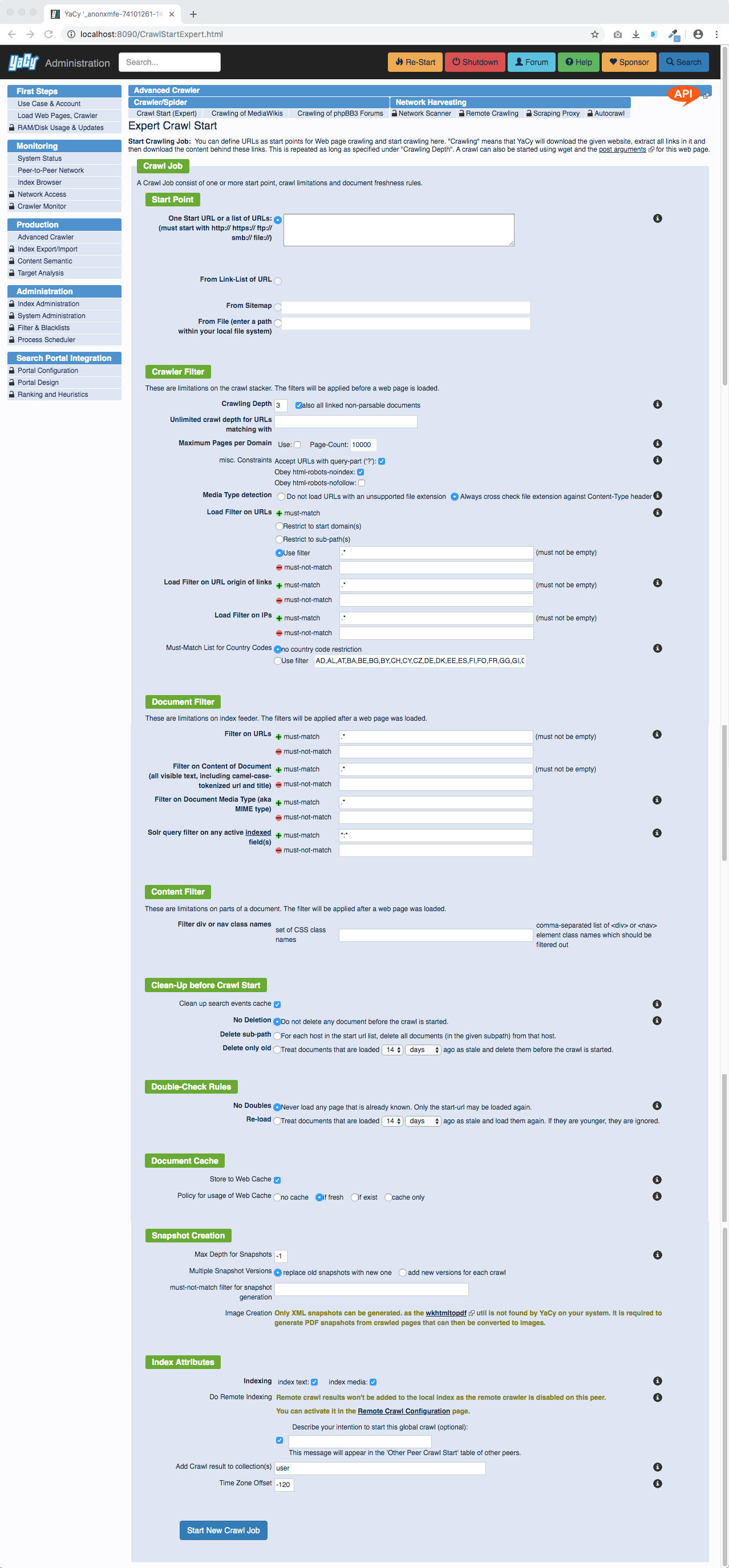
This page is available in Production > Advanced Crawler via the address http://localhost:8090/CrawlStart_p.html and allows you to start new web crawls by creating a new crawling profile. In case an administrator password was setup you have to login as the administrator first.
Crawl Properties
Starting Point
The "Starting Point" at "From URL" defines the page where the crawl is started from (e.g. www.server.com).
- From URL: Enter your website that should be crawled in the form http://www.domain.com or http://www.domain.com/index.html or maybe http://www.domain.com/subfolder/index.html. This will then get indexed with the specified crawl depth.
- From Sitemap: If the domain in "From URL:" lists a sitemap in the robots.txt file this sitemap will be shown here and can be used as a crawl starting point.
- From File: Use a HTML document generated from a script or editor
of your choice. All links that are found in this HTML file via <a
href="http://www.domain.com">Textlink</a> will be automatically
crawled with the crawl depth "1" and indexed. In Linux you can split
a file with
splitin lines. Asplit -l 10000 Links.dbcreated files with each 10000 lines named likeLinks.dbnn.
Create Bookmark
This option works only if a "From URL:" was used as a starting point and automatically adds the URL as a bookmark.
- Title: Use a specific title for the bookmark
- Folder: To crawl this URL regurarly use on the default folders
defined:
- /autoReCrawl/hourly
- /autoReCrawl/daily
- /autoReCrawl/weekly
- /autoReCrawl/monthly
Attention: The Recrawl settings are folder dependant You can change
those settings in the file /DATA/SETTINGS/autoReCrawl.conf.
Crawling Depth
Set the depth for the crawl to define how deep the crawl should be.
- If you just want to index the page defined at the starting point use the crawl depth 0.
- If you just want to index the page defined at the starting point and all directly linked pages use the crawl depth 1.
- If you just want to index the page defined at the starting point and all directly and indirectly linked pages use the crawl depth 2.
- ...
A minimum of 0 is recommended and means that the page you enter under "Starting Point" will be added to the index, but no linked content is indexed. 2-4 is good for normal indexing. Be careful with the depth. Consider a branching factor of average 20; A prefetch-depth of 8 would index 25.600.000.000 pages, maybe this is the whole WWW.
Must-Match Filter
With these three options you can select how the crawler is accepting URLs:
- Use filter The filter is a regular expression that must match with the URLs which are used to be crawled and the default setting is 'catch all' (.*).
Example: to allow only urls that contain the word 'science', set the
filter to .*science.*.
- Restrict to start domain With this setting the crawler will only accept URLs with the domain of the start URL. It is recommended to increase the crawling depth here to fully crawl a single domain.
Example: A crawl From URL: http://www.server.com/folder/index.html
would also crawl and index all linked pages with the active filter
.*www.server.com.*
- Restrict to sub-path With this setting the crawler will only accept URLs with the current sub-folder of the start URL.
Example: A crawl From URL: http://www.server.com/folder/index.html would also crawl and index all linked pages with the active filter http://www.server.com/folder/.*
Must-Not-Match Filter
This filter must not match to allow that the page is accepted for crawling. The empty string is a never-match filter which should do well for most cases. If you don't know what this means, please leave this field empty.
Re-crawl known URLs
If you use this option, web pages that are already existent in your database are crawled and indexed again. It depends on the age of the last crawl if this is done or not: if the last crawl is older than the given date, the page is crawled again, otherwise it is treated as 'double' and not loaded or indexed again.
Auto-Dom-Filter
This option will automatically create a domain-filter which limits the crawl on domains the crawler will find on the given depth. You can use this option i.e. to crawl a page with bookmarks while restricting the crawl on only those domains that appear on the bookmark-page. The adequate depth for this example would be 1. The default value 0 gives no restrictions.
Maximum Pages per Domain
You can limit the maximum number of pages that are fetched and indexed from a single domain with this option. You can combine this limitation with the 'Auto-Dom-Filter', so that the limit is applied to all the domains within the given depth. Domains outside the given depth are then sorted-out anyway.
Accept URLs with '?' / dynamic URLs
A questionmark is usually a hint for a dynamic page. URLs pointing to dynamic content should usually not be crawled. However, there are sometimes web pages with static content that is accessed with URLs containing question marks. If you are unsure, do not check this to avoid crawl loops.
Example: www.domain.com/index.php?page=start
Store to Web Cache
Use YaCy as a proxy cache at the same time. So crawled and indexed pages are saved in the proxy cache to speed up the access in case of another request for the same page. This option is used by default for proxy prefetch, but is not needed for explicit crawling.
Do Local Indexing
This enables indexing of the wepages the crawler will download. This should be switched on by default, unless you want to crawl only to fill the Document Cache without indexing. The settings allows separate options for text and other media formats.
Do Remote Indexing
Here you can select who gets this "crawl job". If checked, the crawler will contact other peers and use them as remote indexers for your crawl. If you need your crawling results locally, you should switch this off. Only senior and principal peers can initiate or receive remote crawls. A YaCyNews message will be created to inform all peers about a global crawl, so they can omit starting a crawl with the same start point.
Exclude static Stop-Words
This can be useful to circumvent that extremely common words are added to the database, i.e. "the", "he", "she", "it"... To exclude all words given in the file yacy.stopwords from indexing, check this box.
Now just click on "Start New Crawl" and your YaCy server starts indexing this page. The progress of the crawl can be seen if you select Index Control - Crawler Monitor, or Index Control - Crawl Results from the menu panel on the left side.
Converted from https://wiki.yacy.net/index.php?title=En:CrawlStart_p, may be outdated