
Vizualizace Internetu
Motto: Cokoliv vûÀs napadne, uéƒ nákdo zrealizoval. Originalita vaaûÙ myalenky je jen zdûÀnûÙ, plynoucûÙ zô nedostatku hledûÀnûÙ.
Internet a struktura
Internet, jak je notoricky znûÀmo, vznikl zô americkûˋ armûÀdnûÙ sûÙtá ARPANET vô dobá, kdy armûÀda zaáûÙnala koordinovat svûˋ akce pomocûÙ poáûÙtaáé₤. Do tûˋ doby nejznûÀmájaûÙm konceptem podobnûˋho éûÙzenûÙ byly megapoáûÙtaáe, majûÙcûÙ na starost vaechno, blûÙéƒûÙcûÙ se péedstavá CentrûÀlnûÙho mozku lidstva. Kdyby armûÀda byla éûÙzena jednûÙm takovû§mto superpoáûÙtaáem, bylo by nutnûˋ ho umûÙstit na nájakûˋ konkrûˋtnûÙ mûÙsto - staáil by jedinû§ jadernû§ vû§buch, nebo odéûÙznutûÙ komunikace a éûÙzenûÙ by bylo vûÀéƒná naruaeno. NamûÙsto toho americkûˋ ministerstvo obrany vyvinulo systûˋm, kterû§ byl decentralizovanû§. Jednotlivûˋ uzly (servery) byly umûÙstány na zûÀkladnûÀch po celû§ch Spojenû§ch stûÀtech, nákterûˋ vô letadlech, na lodûÙch, propojenûˋ navzûÀjem komunikaánûÙ sûÙtûÙ se strukturou podobnou pavuáiná. Tento systûˋm mál zajistit, éƒe péi vyéazenûÙ jednoho, nákolika, ái dokonce mnoha prvké₤ sûÙtá bude celek - podobná jako lidskû§ mozek - stûÀle provozuschopnû§.
DneanûÙ Internet se konceptu pavuáiny podobûÀ vzdûÀlená. V komeránûÙ sfûˋée se zô topologie stala spûÙae hvázda, tedy û¤tvar zûÀvislû§ na centru. Vô áeskûˋ republice je napéûÙklad takovû§m centrem Praha a nákolik mûÙst vô nûÙ - péi drobnájaûÙm poéƒûÀru by tato centralizace mohla péinûˋst vûÀéƒnûˋ problûˋmy.
PéûÙchod komerce a rozaûÙéenûÙ vizuûÀlnûÙch operaánûÙch systûˋmé₤ ale péineslo i nespornou vû§hodu - vizualizaci do tûˋ doby textovûˋho prostéedûÙ Internetu.
Vô tûˋto prûÀci se budeme zabû§vat péedevaûÙm World Wide Webem. Za jeho zûÀkladnûÙ element mé₤éƒeme povaéƒovat textovou strûÀnku doplnánou grafikou, péûÙpadná animacûÙ. ZûÀkladnûÙ vû§hodou WWW je jeho hypertextovûÀ podstata - jakûÀkoliv áûÀst strûÀnky mé₤éƒe odkazovat na jinûˋ mûÙsto na jinûˋ strûÀnce. To vytvûÀéûÙ strukturu hlavná obsahovou, nezûÀvislou na geografickûˋm rozmûÙstánûÙ propojenû§ch strûÀnek.
Jak jiéƒ vyplû§vûÀ ze zûÀkladnûÙ technickûˋ struktury uspoéûÀdûÀnûÙ souboré₤ na poáûÙtaái/sûÙti (model "strom"), lze nahlûÙéƒet na obsah sûÙtá po jednotlivû§ch serverech, tedy uvidûÙme jednotlivûˋ sloéƒky obsahujûÙcûÙ podsloéƒky atd. to vae v rûÀmci jednotlivû§ch domûˋn (apiáka stromovûˋho schûˋmatu). TakovûÀto strukturace se dodnes vyuéƒûÙvûÀ ve FTP, ale je zéejmûˋ, éƒe pro praktickou prezentaci je naprosto nepouéƒitelnûÀ. Uéƒ proto, éƒe internet ve svûˋ funkánosti nenûÙ jen schrumûÀéƒ samostatnû§ch souboré₤.
Pé₤vodná bylo téeba kô zûÙskûÀnûÙ informace znûÀt adresu, na kterûˋ se tato informace nachûÀzûÙ. Adresa se dala zjistit vô tiatánûˋm mûˋdiu nebo ji ve formá odkazu zveéejnil autor spéûÙznánûˋ strûÀnky.
To je samozéejmá pro hledûÀnûÙ dosti nepraktickûˋ - zaáaly vznikat rozcestnûÙky ve stylu HledûÀte-li náco o kvantovûˋ fyzice, najdete to na táhle strûÀnkûÀch:... udréƒovanûˋ nadaenci. Vô tûˋ dobá nebyl jeatá problûˋm ruáná udréƒovat i zpátnûˋ odkazy na strûÀnky tûˋmaticky nadéazenûˋ ( Hezkû§ rozcestnûÙk o kvantovûˋ fyzice najdete na:... ).
Sô dalaûÙm rozaiéovûÀnûÙm poátu webovû§ch strûÀnek vznikly i servery specializovanûˋ jako adresûÀée. VychûÀzely dokonce i adresûÀée papûÙrovûˋ a jeatá péed nákolika lety se nezdûÀlo velkûˋmu vydavateli poáûÙtaáovû§ch knih absurdnûÙ vydûÀvat zlatûˋ strûÀnky pro Internet. Brzy se zjistilo, éƒe takovû§ server nemé₤éƒe spravovat skupina lidûÙ surfujûÙcûÙch pro expandujûÙcûÙm Webu, ale odkazy musûÙ péidûÀvat sami lidûˋ, kteéûÙ strûÀnky vytvûÀéejûÙ. Servery jako Yahoo ái Seznam se staly pro mnoho uéƒivatelé₤ vû§chozûÙm mûÙstem pro prohlûÙéƒenûÙ Webu. Takovûˋ sluéƒby majûÙ kromá prohledûÀvûÀnûÙ adresûÀée takûˋ strom kategoriûÙ a podkategoriûÙ strûÀnek, kterûˋ uéƒ vytvûÀéejûÙ hierarchickou strukturu (Seznam ~Spoleánost ~Ekologie ~EkologickûÀ hnutûÙ). Takovû§ strom se ale mûÀlokdy zobrazuje jinak neéƒ vô podobá textovûˋho seznamu a zéûÙdka takovû§ seznam obsahuje vûÙce neéƒ jednu û¤roveé zobrazenûÙ. TéûÙdánûÙ sice mûÀ logickou strukturu, ale nepostihuje vé₤bec péirozenou strukturu webovû§ch strûÀnek a pohybu uéƒivatelé₤ v nich.
Soubáéƒná a dlouhou dobu nepéûÙlia péesvádáivá se vyvûÙjely vyhledûÀvacûÙ sluéƒby zaloéƒenûˋ na fulltextu neboli vyhledûÀvûÀnûÙ konkrûˋtnûÙch slov vô plnû§ch textech strûÀnek. Fulltexovûˋ servery musely vyvinout speciûÀlnûÙ roboty - virtuûÀlnûÙ uéƒivatele, pavouky, crawlery - kterûˋ prohlûÙéƒejûÙ web a stahujûÙ z náj vaechny textovûˋ informace. NavûÙc vô nalezenû§ch strûÀnkûÀch vyhledajûÙ hypertextovûˋ odkazy a nûÀsledujûÙ je. KonkrûˋtnûÙ strûÀnku tedy do vyhledûÀvacûÙho serveru nemusûÙ nikdo registrovat, staáûÙ, kdyéƒ na nûÙ vede odkaz zô nákterûˋ strûÀnky navatûÙvenûˋ pavoukem. To mimo jinûˋ vede i kô tomu, éƒe strûÀnky, na náéƒ odkaz nevede, jakoby neexistovaly.
UmûÙstánûÙ odkazé₤ na spéûÀtelenûˋ servery, na strûÀnky kamarûÀdé₤ a na podobná zamáéenûˋ strûÀnky je vaak na Webu jiéƒ delaûÙ dobu konsensem.
Fulltextovûˋ crawlery zatûÙm nejspûÙa nejdokonaleji postihujûÙ strukturu a provûÀzanost webovûˋ pavuáiny, akoda, éƒe nenabûÙzejûÙ éƒûÀdnou vizualizaci tûˋto struktury (o nákterû§ch uskuteánánû§ch pokusech se zmûÙnûÙme dûÀle).
Dé₤vodem, proá stûÀly fulltextovûˋ vyhledûÀvaáe dlouho mimo pozornost byla jejich malûÀ efektivnost - na dotaz dostaneme jen seznam strûÀnek vybranû§ch jen podle poátu vû§skyté₤ hledanû§ch slov. NesmûÙrnou vû§hodou ale je moéƒnost ptûÀt se na pojem bez znalosti kontextu. NevûÙme-li vé₤bec nic o ûdinovi, nenapadlo by nûÀs vô klasickûˋm webovûˋm katalogu navatûÙvit kategorii NûÀboéƒenstvûÙ ~Mytologie ~GermûÀnskûÀ mytologie .
Snahy o zefektivnánûÙ fulltextu, kterû§ kô báéƒnû§m tûˋmaté₤m vracel dosti irelevantnûÙ informace, aly pées sledovûÀnûÙ vzûÀjemnûˋho propojenû§ webovû§ch strûÀnek, ale takûˋ pées sledovûÀnûÙ uéƒivatelé₤ pracujûÙcûÙch sô vyhledûÀvaáem.
VyhledûÀvacûÙ algoritmy zaáaly zohledéovat napéûÙklad tato otûÀzky:
vedou na tuto strûÀnku odkazy zô jinû§ch strûÀnek? Kolik a odkud?
vrûÀtil se uéƒivatel vô krûÀtkûˋ dobá na vyhledûÀvaá? (byl spokojen se vztahem: hledanûÀ klûÙáovûÀ slova - nalezenûÀ strûÀnka?)
jakûÀ dalaûÙ slova tento uéƒivatel hledal?
vô jakûˋm vztahu jsou hledanûÀ slova na strûÀnce? blûÙzko / daleko od sebe, jsou souáûÀstûÙ jednûˋ váty? jak áasto se vyskytujûÙ? jak áasto se vyskytujûÙ slova zô podobnûˋho tematickûˋho okruhu?
Struktura se mánûÙ zô lineûÀrnûÙho seznamu vô jakûˋsi shluky podle tûˋmat, nûÀvatáv uéƒivatelé₤, vzûÀjemnû§ch odkazé₤, vû§skyté₤ podobnû§ch slov, shluky sloéƒitá vzûÀjemná propojenûˋ a provûÀzanûˋ.
Vû§stupem pak mé₤éƒe péi hledûÀnûÙ klûÙáovûˋho slova Hitler bû§t doléujûÙcûÙ box ve stylu: DalaûÙ odkazy na informace o: Nacismu, Faaismu, Druhûˋ svátovûˋ vûÀlce . Péi prohlûÙéƒenûÙ katalogu knih ái CD se objevujûÙ nabûÙdky jako: Uéƒivatelûˋ, kteéûÙ si koupili tuto knihu se zajûÙmali takûˋ o:...
Bohuéƒel ani tato struktura nenûÙ ve vyhledûÀvaáûÙch prezentovûÀna éƒûÀdnû§m vizuûÀlnûÙm zpé₤sobem - jsou to zase jen trochu jinak setéûÙdánûˋ odkazy.
Vizualizace cest uéƒivatelé₤
Pokaéƒdûˋ, kdyéƒ prochûÀzûÙte Web, zanechûÀvûÀte po sobá stopy. ZdûÀ se û¤áelnûˋ tyto stopy zpracovûÀvat, protoéƒe nûÀm mohou éûÙct jednak náco o áinnosti uéƒivatelé₤ - napéûÙklad o reakcûÙch, schopnosti absorbovat informace, chuti kliknout na nákterûˋ odkazy - a takûˋ o kvalitá strûÀnek - zda jsou sdálnûˋ, srozumitelnûˋ, péitaéƒlivûˋ.
Nákterûˋ zô táchto metod ovlivéujûÙ péûÙmo vzhled ái strukturu strûÀnek, jinûˋ jsou pouze pasivná-statistickûˋ.
NejáastájaûÙm a nejprimitivnájaûÙm sledovûÀnûÙm cest uéƒivatelé₤ je poáûÙtadlo péûÙstupé₤ - vlastná pré₤tokomár. To nákteéûÙ autoéi vystavujûÙ na svû§ch strûÀnkûÀch jako reklamu - podûÙvejte se, kolik lidûÙ tu uéƒ bylo.
Ale to nenûÙ vaechno, co lze zô vaaûÙ nûÀvatávy webu zjistit. Server vûÙ, jakû§ pouéƒûÙvûÀte prohlûÙéƒeá, zô jakûˋ jste zemá, jakû§ mûÀte péedvolenû§ jazyk, kterû§ operaánûÙ systûˋm pouéƒûÙvûÀte i zô kterûˋ strûÀnky jste péiael. Pokud jste péiael zô vyhledûÀvacûÙho serveru, dokûÀéƒe i zjistit, jakûÀ slova jste vyhledûÀval.
Tyto informace se na naprostûˋ vátainá serveré₤ skladujûÙ vô archivnûÙch zûÀznamech zvanû§ch logy. NákteéûÙ administrûÀtoéi je odstraéujûÙ, ale stûÀle vûÙce serveré₤ se snaéƒûÙ tyto logy nájak statisticky zpracovat a pouéƒûÙt jako zpátnou vazbu.
Péestoéƒe vstupnûÙ data by umoéƒéovala velmi podrobnou analû§zu putovûÀnûÙ uéƒivatelé₤ po strûÀnkûÀch serveru (a vô péûÙpadá reklamnûÙch serveré₤, kterûˋ majûÙ svûˋ prouéƒky rozmûÙstány na kdejakûˋ strûÀnce, i po vûÙce áûÀstech webu) a jejich chovûÀnûÙ, báéƒná pouéƒûÙvanûˋ programy zobrazujûÙ pouze povrchnûÙ vû§stupy srovnatelnûˋ sô kolûÀái sledovanosti televiznûÙch programé₤. DûÀ se sestavit éƒebéûÙáek nûÀvatávnosti jednotlivû§ch strûÀnek, podûÙl uéƒivatelé₤ sô ré₤znû§mi prohlûÙéƒeái, zjistit kdy jsou uéƒivatelûˋ nejaktivnájaûÙ, kterou hodinu ve dni, kterû§ den vô tû§dnu - vae vô péehlednû§ch grafech, ale to je vae.
KomeránûÙ (a nûÀm nedostupnûÀ) serverovûÀ éeaenûÙ nûÀstroje na sledovûÀnûÙ individuûÀlnûÙch cest uéƒivatelé₤ a jejich sumarizaci nabûÙzejûÙ a ti, kdo je pouéƒûÙvajûÙ, mluvûÙ o velkûˋm zvû§aenûÙ dostupnosti relevantnûÙch informacûÙ pro uéƒivatele . Tyto analû§zy se vaak do zobrazenûÙ webu promûÙtajûÙ jen zprostéedkovaná, skrze tvé₤rce strûÀnek.
JednûÙm zô péûÙkladé₤, jak mé₤éƒe pohyb uéƒivatelé₤ péûÙmo ovlivnit áûÀst struktury sûÙtá, je kolonka nejátenájaûÙ álûÀnky na nákterû§ch webovû§ch áasopisech. Zô praxe ovaem plyne, éƒe na tûˋto pozici se dréƒûÙ stûÀle titûˋéƒ favoritûˋ, protoéƒe nejátenájaûÙ jsou nejatraktivnájaûÙ a tudûÙéƒ stûÀle átenájaûÙ... NevûÙc kromá masovosti nûÀvatáv uéƒivatelé₤ to neukazuje nic o struktuée ani vzûÀjemnû§ch vztazûÙch webé₤.
Kô tomu bychom chtáli smáéovat prûÀvá naaûÙm modelem.
NejadekvûÀtnájaûÙ vizualizace internetu aneb naae vize ...
Jak jiéƒ bylo naznaáeno, dosavadnûÙ orientaánûÙ pomé₤cky pro prûÀci s webem zdaleka nepostihujûÙ jeho strukturu jako dynamickou a (vlastná) nekoneánározmárnou sûÙéË. Proto jsme na zûÀkladá moéƒnosti monitorovûÀnûÙ pohybu uéƒivatelé₤ (kterû§ podle nûÀs nejlûˋpe vypovûÙdûÀ o spéûÙznánosti jednotlivû§ch strûÀnek) vyvinuli uráitou vizi, jak by mála vypadat nejadekvûÀtnájaûÙ, ale stûÀle jeatá álovákem snadno pochopitelnûÀ, vizualizace. Byla by zaloéƒena na pouéƒûÙvanosti jednotlivû§ch linké₤ a strûÀnek, coéƒ by se projevilo vô prostorovûˋm zobrazenûÙ jako jejich zvátaovûÀnûÙ a péibliéƒovûÀnûÙ. Péedstavme si, éƒe jedna strûÀnka je péirozená zastrukturovanûÀ do sûÙtá pomocûÙ jiéƒ klasickûˋ sekce odkazy (linky&) vedoucûÙ na podobnûÀ autorovi znûÀmûÀ mûÙsta na webu. Tedy uéƒivatel, kterû§ se zde nachomû§tne a pouéƒije nájakû§ zô nich, tûÙm poskytne informaci ael jsem odtud tam. Ta samotnûÀ jeatá nemûÀ takovou vypovûÙdacûÙ hodnotu, ale pomocûÙ dlouhodobájaûÙho sledovûÀnûÙ takovûˋho chovûÀnûÙ uéƒivatelé₤ by bylo moéƒno dosûÙci uráitûˋho obrazu, ponávadéƒ uéƒ existence takovûˋho propojenûÙ by strûÀnky sbliéƒovala. Podle zûÀkonitosti, éƒe pré₤márnû§ surfer navatávuje strûÀnky vátainou sô nájakû§m zûÀmárem a cûÙlem by se tak tvoéily shluky spéûÙznánû§ch sajté₤, ovaem jejich spéûÙznánost by byla áistá (nad)subjektivnûÙ, tvoéena realitou. Ovaem takto by byla dynamika omezena pouze na autorem péeduráenûˋ linky, coéƒ by bylo péûÙlia neobjektivnûÙ. PéiblûÙéƒit se ideji webu by alo pomocûÙ aktivnûÙch formulûÀéé₤, pomocûÙ kterû§ch by mohli uéƒivatelûˋ sami péidûÀvat odkazy a zaáleéovat tak strûÀnky do globûÀlnûÙho kontextu. Podobnûˋ formulûÀée uéƒ dûÀvno fungujûÙ, napéûÙklad vô podobá tolik oblûÙbenû§ch questbooké₤ (- dokonce i za û¤áelem nûÀm podobnû§m: jako napéûÙklad na www.totem.cz apod.). Ovaem dosavadnûÙ podoba je klasickû§ seznam, maximûÀlná se strukturou stromu (péi moéƒnosti reagovat na cizûÙ péûÙspávky) a funguje samozéejmá pouze vô rûÀmci tûˋ kterûˋ strûÀnky. Vô onûˋ hypotetickûˋ roviná idejûÙ/strûÀnek by takovûˋto péûÙspávky tvoéily cesty na dalaûÙ a dalaûÙ mûÙsta a zpéeséovaly by tak polohu tûˋ kterûˋ strûÀnky. ExemplûÀrná si to lze péedstavit tak, éƒe kaéƒdûÀ strûÀnka je vô prostoru prezentovûÀna dejme tomu koulûÙ, jejûÙéƒ velikost odpovûÙdûÀ navatávovanosti, a zô nûÙéƒ vybûÙhajûÙ vaechny linky na dalaûÙ takovûˋ koule. Podle uéƒûÙvanosti takovû§ch páainek se tyto proalapûÀvajûÙ tûÙm vûÙce, áûÙm se pouéƒûÙvajûÙ, a reûÀlná tak spéûÙznánûˋ koule péibliéƒujûÙ kô sobá. Vhodnûˋ by bylo do tohoto prostoru implementovat princip konstantnûÙho rozpûÙnûÀnûÙ (stejná jako ve fyzice), aby se tento prostor stûÀle nesmraéËoval soustavnû§m uéƒûÙvûÀnûÙm a aby se zô náj po áase nestala jedna kompaktnûÙ bakule.
Systûˋm by mál bû§t nejlûˋpe decentralizovanû§, nezûÀvislû§ na konkrûˋtnûÙ serverovûˋ platformá, na jedinûˋm serveru ái serverovûˋ farmá - kdyéƒ bude roztrouaenû§ po svátá, bude daleko stabilnájaûÙ a obtûÙéƒná zbouratelnû§. Takûˋ vátaina vû§poáté₤ by mála bû§t co nejmûˋná zûÀvislûÀ na sobá navzûÀjem - vô zûÀjmu efektivity.
ûskalûÙ vizualizace internetu
Popsanûˋ trojrozmárnûˋ vizualizace majûÙ jedno spoleánûˋ: dréƒûÙ se euklidovskûˋho ( reûÀlnûˋho ) pojetûÙ prostoru. Ten ovaem nedostaáuje vô plnûˋ mûÙée kô bezezbytkovûˋmu znûÀzornánûÙ vaech dostupnû§ch û¤dajé₤. NapéûÙklad, vrûÀtûÙm-li se kô naaûÙ vizi, péi znûÀzoréovûÀnûÙ frekventovanosti tras péibliéƒovûÀnûÙm je nemoéƒnûˋ zahrnout do jednotnûˋho prostoru i informaci o (péevlûÀdajûÙcûÙm) smáru pohybu. Pravdá bliéƒaûÙ by byl model, kde by pouéƒûÙvanájaûÙ linka jednûÙm smárem byla krataûÙ neéƒ opaánû§m i kdyby se jednalo o tu samou. Jedinûˋ pro álováka snadno péedstavitelnûˋ éeaenûÙ je interná zobrazovat okolûÙ kaéƒdûˋ strûÀnky jakoby zô pohledu z-nûÙ-ven. Jen tak je moéƒno dosûÀhnout, aby se ta samûÀ vzdûÀlenost jevila jednou delaûÙ, podruhûˋ krataûÙ.
Je moéƒnûˋ takovû§ model péipodobnit monûÀdûÀm. Kdyby byla kaéƒdûÀ strûÀnka bublinou a odrûÀéƒela svûˋ specifickûˋ okolûÙ, bylo by lze napéûÙklad znûÀzornit blûÙzkost jasem vnájaûÙ bubliny.
Samozéejmá jako kaéƒdûÀ reflexe skuteánosti, majûÙ i vaechny modely internetu svûÀ pozitiva i negativa.
Koncepce másta
Ponákud staraûÙ koncepce, kterûÀ by byla sice vizuûÀlná zajûÙmavájaûÙ (koule a áûÀry toho na prvnûÙ pohled tolik neprozradûÙ, zvlûÀaéË, kdyéƒ visûÙ vô prostoru, sô áûÙméƒ álovák tolik zkuaenostûÙ zô reûÀlnûˋho éƒivota nemûÀ) je koncepce másta. Takovû§ nûÀpad by zrealizovanû§ obsahoval veéejnû§ virtuûÀlnûÙ prostor, uráenû§ kô trojrozmárnû§m prezentacûÙm sem umûÙstánû§ch strûÀnek. ZajûÙmavûÀ by byla otûÀzka, jak by majitelûˋ webé₤ trojrozmárná prezentovali svûˋ strûÀnky (náco mezi trojrozmárnou ikonou a billboardem), ovaem pro nûÀs je zajûÙmavájaûÙ problûˋm jak a kam by je vô kontextu zaéazovali. Lehkû§ nûÀznak takovûˋ ideje lze nalûˋzt na www.map.net. Vlastná by tak nevzniklo nic jinûˋho, neéƒ trojrozmárnû§ portûÀl, kde by (hypoteticky, praxe by byla dost moéƒnûÀ odlianûÀ) vznikaly átvrti podle spéûÙznánosti. ái by se zde naopak projevily tendence bû§t vû§luánû§ ve svûˋm okolûÙ. KaéƒdopûÀdná takovûÀ prezentace by vypovûÙdala mnohûˋ zejmûˋna o majitelûÙch dokumenté₤, zvlûÀatá, podaéilo-li by se zde vytvoéit cosi jako tréƒnûÙ prostéedûÙ - pomocûÙ placenosti pozemké₤ , kterûÀ by musela bû§t zpoáûÀtku uráena. KoneánûÀ vize pak vypadûÀ jako skuteánûˋ másto sô centrem (kde jsou bohatûˋ komeránûÙ servery ái weby bohatû§ch korporacûÙ, a perifernûÙ slumy bezplatnû§ch osobnûÙch strûÀnek&. Tato vize je rovnáéƒ áûÀsteáná uskuteánánûÀ; je vyvinut a funkánûÙ program ActiveWords (www.activeworlds.com) , kterû§ umoéƒéuje modelovûÀnûÙ 3D prostéedûÙ i sô vizuûÀlnûÙmi prezentacemi nûÀvatávnûÙké₤ (avataéi) a implementacûÙ textu (coéƒ je asi hlavnûÙ vû§hoda proti VRML&). Ovaem tento program zatûÙm slouéƒûÙ spûÙae kô tvorbá krûÀsnû§ch barevnû§ch osobnûÙch strûÀnek (placenû§ch), neéƒ ke komplexnûÙmu pokusu o soubor internetovû§ch zdrojé₤.
Jako konkrûˋtnûÙ zpé₤sob vizualizace se jazyk VRML sûÀm nabûÙzûÙ - je nejrozaûÙéenájaûÙm a alespoé áûÀsteáná vô internetovû§ch prohlûÙéƒeáûÙch podporovanû§m jazykem pro popis 3D sváta. Bohuéƒel uéƒ pro svou linearitu je pro naae û¤áely nepouéƒitelnû§ - do památi poáûÙtaáe uéƒivatele surfujûÙcûÙho svátem VRML se musûÙ naáûÙst véƒdy celû§ prostor, coéƒ je u prostoru nekoneánûˋho nebo péinejmenaûÙm velmi rozsûÀhlûˋho nepéekonatelnû§ problûˋm. Zô tûˋhoéƒ dé₤vodu narazili na problûˋmy i tvé₤rci áeskûˋho systûˋmu eAgora (http://www.palacakropolis.cz/agora/index.php), kterû§ by mál bû§t virtuûÀlnûÙ verzûÙ praéƒskûˋho PalûÀce Akropolis, mála by se vô nám odehrûÀvat setkûÀvûÀnûÙ jednotlivû§ch nûÀvatávnûÙké₤, resp. jejich avataré₤, péûÙmûˋ péenosy koncerté₤ vô Akropoli a vzniknout by málo i spojenûÙ sô obdobnû§mi evropskû§mi centry. Problûˋm s linearitou VRML vaak tvé₤rci systûˋmu nemohli péekonat a museli prostor rozdálit do uzavéenû§ch mûÙstnostûÙ . Tohle nenûÙ fotka PalûÀce Akropolis. Je to jeho VRML model:
VRML je takûˋ relativná velmi nûÀroánû§ na vû§poáetnûÙ vû§kon klientskû§ch poáûÙtaáé₤. VhodnájaûÙm by se jevil napéûÙklad modifikovanû§ engine zô 3D poáûÙtaáovûˋ hry.
Péedealûˋ pokusy o vizualizaci struktury Webu
Báhem nadaenûˋho rozvûÙjenûÙ naaeho projektu jsme
samozéejmá narazili i na projekty obdobnûˋ (viz motto).
Nejprve se krûÀtce zastavûÙme u vizualizace fyzickûˋ
struktury SûÙtá. Ta je pomárná zavedenûÀ, a pouéƒûÙvanûÀ
péi samotnûˋ vû§stavbá sûÙtûÙ, omezenûÀ mé₤éƒe bû§t jen
sloéƒitostûÙ,jako napé. tato podoba americkûˋ satelitnûÙ
sûÙtá NSFNET: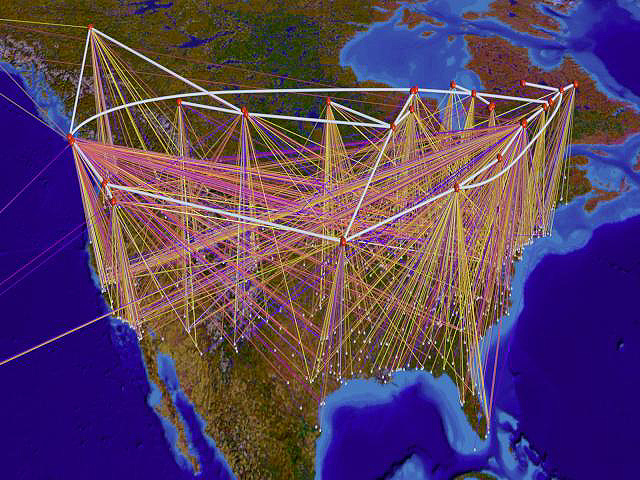
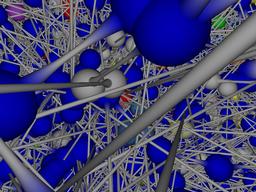
Ta mûÀ vaak sô virtuûÀlnûÙm prostorem spoleánou jen hardwarovou zûÀkladnu. Kô daleko zajûÙmavájaûÙmu experimentu se odhodlal sûÙéËovû§ odbornûÙk Steve Coast (http://www.fractalus.com/steve). Chtál prozkoumat skuteánou strukturu Internetu jako virtuûÀlnûÙho sváta - vyslal tedy do sváta éûÀdová miliû°ny paketé₤ (malûˋ shluky dat), sledoval jejich cesty, dobu odezvy. Vû§sledky uloéƒil do databûÀze a pomocûÙ vizualizaánûÙch nûÀstrojé₤ (2d i 3d) se pokusil zûÙskanûˋ informace o struktuée sûÙtá prezentovat. Kaéƒdû§ server zobrazil jako kuliáku a kuliáky pospojoval linkami - byly od sebe daleko nikoliv vô zûÀvislosti na geografickûˋ vzdûÀlenosti, ale na dobá putovûÀnûÙ paketé₤ mezi nimi. Jedno ze zobrazenûÙ (na náméƒ je zachycena samozéejmá jen áûÀst SûÙtá) vypadûÀ takto:

Do zdûÀnlivá nepéehlednûˋ struktury se mé₤éƒeme dûÙky VRML a QuickTime animacûÙm, kterûˋ Steve péipravil, ponoéit i hloubáji:
PéûÙjemnû§m péekvapenûÙm pro nûÀs takûˋ bylo, éƒe péestoéƒe fulltextovûˋ vyhledûÀvaáe implicitná éƒûÀdnou poéûÀdnou vizualizaci nepodporujûÙ, existuje Java-applet Antona Leuskiho Lighthouse, kterû§ dokûÀéƒe vû§sledky zûÙskanûˋ zô nákolika fulltexté₤ graficky zobrazit - jednotlivûˋ strûÀnky jsou majûÙ podobu kuliáek a aplikace je clusteruje do hnûÙzd (clusteré₤) podle jejich vzûÀjemnûˋ tûˋmatickûˋ blûÙzkosti ái vzdûÀlenosti. Jako potenciûÀlnûÙ konkurence musûÙme konstatovat, éƒe ani tento systûˋm zatûÙm nefunguje véƒdy û¤plná stoprocentná. NûÀstroj je toale zajûÙmavû§ a navûÙc spustitelnû§ péûÙmo zô webu (http://toowoomba.cs.umass.edu/~leouski/lighthouse/)
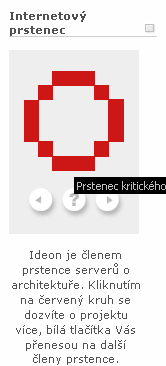
Co se tû§áe struktury pawuáiny samotnûˋ, znûÀmûˋ jsou systûˋmy webovû§ch prstencé₤. Prstenec je obvykle nájak tûˋmaticky zamáéen, jeho áleny jsou webovûˋ strûÀnky, na nichéƒ je umûÙstán odkaz na prstenec samotnû§. DûÙky aktivnûÙmu systûˋmu mûÀ átenûÀé tûˋto strûÀnky pak moéƒnost péejûÙt na péedchozûÙ i nûÀsledujûÙcûÙ sajt vô prstenci, nebo si vylosovat odkaz nûÀhodnû§. Ve svátá jsou oblûÙbenûˋ prstencovûˋ servery jako www.webring.org.
ChybûÙ-li uéƒivateli péehlednûÀ mapa webu, mé₤éƒe si ji
sûÀm sestavit pomocûÙ programu Internet Cartographer
od spoleánosti Inventix (http://www.inventix.com/ --
kô vyzkouaenûÙ zdarma, jinak stojûÙ necelû§ch $50).
Cartographer se spouatûÙ spoleáná sô Internetovû§m
prohlûÙéƒeáem a sleduje, jakûˋ adresy si uéƒivatel
prohlûÙéƒûÙ. Zô nich pak sestavuje jednak katalog a za
druhûˋ sûÙéË - mapu uéƒivatelem prozkoumanûˋho
kyberprostoru. Bohuéƒel ani tento systûˋm nenûÙ zcela
doveden dokonce, téebaéƒe vypadûÀ dosti slibná.
A koneáná zde musûÙm zmûÙnit jeden projekt, kterû§ je sice stûÀle ve vû§voji, ovaem tûˋmáé bezezbytková postihuje naai ideu adekvûÀtnûÙ vizualizace. JednûÀ se projekt vzniklû§ u péûÙleéƒitosti TéetûÙ mezinûÀrodnûÙ World-Wide Web konference konanûˋ vô roce 95 vô Darmstadtu. Je to program nazvanû§ HyperSpace: Web Browsing with Visualisation. I kdyéƒ se vô zûÀsadá jednûÀ pouze o dosud nenaplnánû§ koncept, naaûÙ vizi boptnavûˋho a proalapûÀvacûÙho systûˋmu rozvûÀdûÙ tento moéƒnûÀ i dûÀl, neéƒ jsme uáinili my. Objevil jsem ho na http://www.igd.fhg.de/archive/1995_www95/proceedings/posters/35/index.html a upéûÙmná, péinesl mi znaánûˋ zklamûÀnûÙ, ponávadéƒ jak pravûÙ motto, spadla vidina geniality. Na druhou stranu je potáaujûÙcûÙ, éƒe takovûˋto projekty probûÙhajûÙ a éƒe je tedy na áem stavát a éƒe najûÙ (byéË tûˋmáé minimûÀlnûÙ) publicitu. Jako mekku aûÙéûÙcûÙ toto tûˋma pro veéejnost musûÙm zmûÙnit web http://www.cybergeography.org/atlas/ , ze kterûˋho jsme ke konci prûÀce nejvûÙce áerpali (a kterû§ tuto prûÀci ponákud degradoval co se originality a péûÙnosnosti tû§áe).